

%20--%3E%0A%0A%3Csvg%0A%20%20%20xmlns%3Adc%3D%22http%3A%2F%2Fpurl.org%2Fdc%2Felements%2F1.1%2F%22%0A%20%20%20xmlns%3Acc%3D%22http%3A%2F%2Fcreativecommons.org%2Fns%23%22%0A%20%20%20xmlns%3Ardf%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2F02%2F22-rdf-syntax-ns%23%22%0A%20%20%20xmlns%3Asvg%3D%22http%3A%2F%2Fwww.w3.org%2F2000%2Fsvg%22%0A%20%20%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F2000%2Fsvg%22%0A%20%20%20xmlns%3Axlink%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxlink%22%0A%20%20%20xmlns%3Asodipodi%3D%22http%3A%2F%2Fsodipodi.sourceforge.net%2FDTD%2Fsodipodi-0.dtd%22%0A%20%20%20xmlns%3Ainkscape%3D%22http%3A%2F%2Fwww.inkscape.org%2Fnamespaces%2Finkscape%22%0A%20%20%20width%3D%2285.018593%22%0A%20%20%20height%3D%2225.977255%22%0A%20%20%20id%3D%22svg2%22%0A%20%20%20version%3D%221.1%22%0A%20%20%20inkscape%3Aversion%3D%220.48.4%20r9939%22%0A%20%20%20sodipodi%3Adocname%3D%22LinkedIn.svg%22%3E%0A%20%20%3Cdefs%0A%20%20%20%20%20id%3D%22defs4%22%3E%0A%20%20%20%20%3ClinearGradient%0A%20%20%20%20%20%20%20id%3D%22linearGradient3785%22%3E%0A%20%20%20%20%20%20%3Cstop%0A%20%20%20%20%20%20%20%20%20style%3D%22stop-color%3A%23fefefe%3Bstop-opacity%3A1%3B%22%0A%20%20%20%20%20%20%20%20%20offset%3D%220%22%0A%20%20%20%20%20%20%20%20%20id%3D%22stop3787%22%20%2F%3E%0A%20%20%20%20%20%20%3Cstop%0A%20%20%20%20%20%20%20%20%20style%3D%22stop-color%3A%23ececec%3Bstop-opacity%3A1%3B%22%0A%20%20%20%20%20%20%20%20%20offset%3D%221%22%0A%20%20%20%20%20%20%20%20%20id%3D%22stop3789%22%20%2F%3E%0A%20%20%20%20%3C%2FlinearGradient%3E%0A%20%20%20%20%3ClinearGradient%0A%20%20%20%20%20%20%20inkscape%3Acollect%3D%22always%22%0A%20%20%20%20%20%20%20xlink%3Ahref%3D%22%23linearGradient3785%22%0A%20%20%20%20%20%20%20id%3D%22linearGradient3791%22%0A%20%20%20%20%20%20%20x1%3D%2239.280788%22%0A%20%20%20%20%20%20%20y1%3D%2212.902368%22%0A%20%20%20%20%20%20%20x2%3D%2239.280788%22%0A%20%20%20%20%20%20%20y2%3D%2232.148937%22%0A%20%20%20%20%20%20%20gradientUnits%3D%22userSpaceOnUse%22%0A%20%20%20%20%20%20%20gradientTransform%3D%22matrix(0.721409%2C0%2C0%2C1%2C0.31235938%2C0)%22%20%2F%3E%0A%20%20%20%20%3ClinearGradient%0A%20%20%20%20%20%20%20id%3D%22linearGradient3003%22%0A%20%20%20%20%20%20%20y2%3D%22425.39999%22%0A%20%20%20%20%20%20%20gradientUnits%3D%22userSpaceOnUse%22%0A%20%20%20%20%20%20%20x2%3D%22-395.85001%22%0A%20%20%20%20%20%20%20gradientTransform%3D%22matrix(-0.50335197%2C0%2C0%2C0.50335205%2C-148.17928%2C-158.8132)%22%0A%20%20%20%20%20%20%20y1%3D%22274.70999%22%0A%20%20%20%20%20%20%20x1%3D%22-344.14999%22%3E%0A%20%20%20%20%20%20%3Cstop%0A%20%20%20%20%20%20%20%20%20stop-color%3D%22%23FFF%22%0A%20%20%20%20%20%20%20%20%20offset%3D%220%22%0A%20%20%20%20%20%20%20%20%20id%3D%22stop7%22%20%2F%3E%0A%20%20%20%20%20%20%3Cstop%0A%20%20%20%20%20%20%20%20%20stop-color%3D%22%23FFF%22%0A%20%20%20%20%20%20%20%20%20stop-opacity%3D%220%22%0A%20%20%20%20%20%20%20%20%20offset%3D%221%22%0A%20%20%20%20%20%20%20%20%20id%3D%22stop9%22%20%2F%3E%0A%20%20%20%20%3C%2FlinearGradient%3E%0A%20%20%20%20%3ClinearGradient%0A%20%20%20%20%20%20%20inkscape%3Acollect%3D%22always%22%0A%20%20%20%20%20%20%20xlink%3Ahref%3D%22%23linearGradient3003%22%0A%20%20%20%20%20%20%20id%3D%22linearGradient3377%22%0A%20%20%20%20%20%20%20gradientUnits%3D%22userSpaceOnUse%22%0A%20%20%20%20%20%20%20gradientTransform%3D%22matrix(-0.00402682%2C0%2C0%2C0.00402682%2C-13.36043%2C23.42958)%22%0A%20%20%20%20%20%20%20x1%3D%22-344.14999%22%0A%20%20%20%20%20%20%20y1%3D%22274.70999%22%0A%20%20%20%20%20%20%20x2%3D%22-395.85001%22%0A%20%20%20%20%20%20%20y2%3D%22425.39999%22%20%2F%3E%0A%20%20%20%20%3ClinearGradient%0A%20%20%20%20%20%20%20id%3D%22linearGradient3003-3%22%0A%20%20%20%20%20%20%20y2%3D%22425.39999%22%0A%20%20%20%20%20%20%20gradientUnits%3D%22userSpaceOnUse%22%0A%20%20%20%20%20%20%20x2%3D%22-395.85001%22%0A%20%20%20%20%20%20%20gradientTransform%3D%22matrix(-0.03674469%2C0%2C0%2C0.0367447%2C-5.012456%2C4.0033664)%22%0A%20%20%20%20%20%20%20y1%3D%22274.70999%22%0A%20%20%20%20%20%20%20x1%3D%22-344.14999%22%3E%0A%20%20%20%20%20%20%3Cstop%0A%20%20%20%20%20%20%20%20%20stop-color%3D%22%23FFF%22%0A%20%20%20%20%20%20%20%20%20offset%3D%220%22%0A%20%20%20%20%20%20%20%20%20id%3D%22stop7-6%22%20%2F%3E%0A%20%20%20%20%20%20%3Cstop%0A%20%20%20%20%20%20%20%20%20stop-color%3D%22%23FFF%22%0A%20%20%20%20%20%20%20%20%20stop-opacity%3D%220%22%0A%20%20%20%20%20%20%20%20%20offset%3D%221%22%0A%20%20%20%20%20%20%20%20%20id%3D%22stop9-8%22%20%2F%3E%0A%20%20%20%20%3C%2FlinearGradient%3E%0A%20%20%3C%2Fdefs%3E%0A%20%20%3Csodipodi%3Anamedview%0A%20%20%20%20%20id%3D%22base%22%0A%20%20%20%20%20pagecolor%3D%22%23ffffff%22%0A%20%20%20%20%20bordercolor%3D%22%23666666%22%0A%20%20%20%20%20borderopacity%3D%221.0%22%0A%20%20%20%20%20inkscape%3Apageopacity%3D%220.0%22%0A%20%20%20%20%20inkscape%3Apageshadow%3D%222%22%0A%20%20%20%20%20inkscape%3Azoom%3D%228%22%0A%20%20%20%20%20inkscape%3Acx%3D%2235.729906%22%0A%20%20%20%20%20inkscape%3Acy%3D%227.9624676%22%0A%20%20%20%20%20inkscape%3Adocument-units%3D%22px%22%0A%20%20%20%20%20inkscape%3Acurrent-layer%3D%22layer1%22%0A%20%20%20%20%20showgrid%3D%22false%22%0A%20%20%20%20%20fit-margin-top%3D%220%22%0A%20%20%20%20%20fit-margin-left%3D%220%22%0A%20%20%20%20%20fit-margin-right%3D%220%22%0A%20%20%20%20%20fit-margin-bottom%3D%220%22%0A%20%20%20%20%20inkscape%3Awindow-width%3D%221222%22%0A%20%20%20%20%20inkscape%3Awindow-height%3D%22708%22%0A%20%20%20%20%20inkscape%3Awindow-x%3D%221224%22%0A%20%20%20%20%20inkscape%3Awindow-y%3D%2219%22%0A%20%20%20%20%20inkscape%3Awindow-maximized%3D%220%22%20%2F%3E%0A%20%20%3Cmetadata%0A%20%20%20%20%20id%3D%22metadata7%22%3E%0A%20%20%20%20%3Crdf%3ARDF%3E%0A%20%20%20%20%20%20%3Ccc%3AWork%0A%20%20%20%20%20%20%20%20%20rdf%3Aabout%3D%22%22%3E%0A%20%20%20%20%20%20%20%20%3Cdc%3Aformat%3Eimage%2Fsvg%2Bxml%3C%2Fdc%3Aformat%3E%0A%20%20%20%20%20%20%20%20%3Cdc%3Atype%0A%20%20%20%20%20%20%20%20%20%20%20rdf%3Aresource%3D%22http%3A%2F%2Fpurl.org%2Fdc%2Fdcmitype%2FStillImage%22%20%2F%3E%0A%20%20%20%20%20%20%20%20%3Cdc%3Atitle%20%2F%3E%0A%20%20%20%20%20%20%3C%2Fcc%3AWork%3E%0A%20%20%20%20%3C%2Frdf%3ARDF%3E%0A%20%20%3C%2Fmetadata%3E%0A%20%20%3Cg%0A%20%20%20%20%20inkscape%3Alabel%3D%22Layer%201%22%0A%20%20%20%20%20inkscape%3Agroupmode%3D%22layer%22%0A%20%20%20%20%20id%3D%22layer1%22%0A%20%20%20%20%20transform%3D%22translate(-0.62121129%2C-12.484656)%22%3E%0A%20%20%20%20%3Crect%0A%20%20%20%20%20%20%20style%3D%22fill%3Aurl(%23linearGradient3791)%3Bfill-opacity%3A1%3Bstroke%3A%23e2e2e2%3Bstroke-width%3A1%3Bstroke-linecap%3Around%3Bstroke-linejoin%3Amiter%3Bstroke-miterlimit%3A4%3Bstroke-opacity%3A1%3Bstroke-dasharray%3Anone%22%0A%20%20%20%20%20%20%20id%3D%22rect2985%22%0A%20%20%20%20%20%20%20width%3D%2275%22%0A%20%20%20%20%20%20%20height%3D%2219%22%0A%20%20%20%20%20%20%20x%3D%221.1212113%22%0A%20%20%20%20%20%20%20y%3D%2212.984656%22%0A%20%20%20%20%20%20%20ry%3D%222.1487894%22%0A%20%20%20%20%20%20%20rx%3D%222.1487894%22%20%2F%3E%0A%20%20%20%20%3Ctext%0A%20%20%20%20%20%20%20xml%3Aspace%3D%22preserve%22%0A%20%20%20%20%20%20%20style%3D%22font-size%3A14.40710354px%3Bfont-style%3Anormal%3Bfont-weight%3Anormal%3Bline-height%3A125%25%3Bletter-spacing%3A0px%3Bword-spacing%3A0px%3Bfill%3A%23333333%3Bfill-opacity%3A1%3Bstroke%3Anone%3Bfont-family%3ASans%22%0A%20%20%20%20%20%20%20x%3D%2222.602589%22%0A%20%20%20%20%20%20%20y%3D%2226.791992%22%0A%20%20%20%20%20%20%20id%3D%22text4002%22%0A%20%20%20%20%20%20%20sodipodi%3Alinespacing%3D%22125%25%22%3E%3Ctspan%0A%20%20%20%20%20%20%20%20%20sodipodi%3Arole%3D%22line%22%0A%20%20%20%20%20%20%20%20%20id%3D%22tspan4004%22%0A%20%20%20%20%20%20%20%20%20x%3D%2222.602589%22%0A%20%20%20%20%20%20%20%20%20y%3D%2226.791992%22%0A%20%20%20%20%20%20%20%20%20style%3D%22font-size%3A12px%3Bfont-style%3Anormal%3Bfont-variant%3Anormal%3Bfont-weight%3Abold%3Bfont-stretch%3Anormal%3Bfill%3A%23333333%3Bfill-opacity%3A1%3Bfont-family%3AArial%3B-inkscape-font-specification%3AArial%20Bold%22%3ELinkedIn%3C%2Ftspan%3E%3C%2Ftext%3E%0A%20%20%20%20%3Cimage%0A%20%20%20%20%20%20%20y%3D%2222.680319%22%0A%20%20%20%20%20%20%20x%3D%2269.858215%22%0A%20%20%20%20%20%20%20id%3D%22image3002%22%0A%20%20%20%20%20%20%20xlink%3Ahref%3D%22data%3Aimage%2Fpng%3Bbase64%2CiVBORw0KGgoAAAANSUhEUgAAAKoAAACqCAYAAAA9dtSCAAAABHNCSVQICAgIfAhkiAAAIABJREFU%20eJztnXl4E9Xex7%2BzJE2TbqQLBGiBIrQFikUWsSxWKSIoFMSFRa6yiYoXFMUFxKuooKIICq8ioiJC%20uQIioCDWAlcB2ZRVoBVQCrR0oXRvtpnz%2FpFm2mmWJmmWUefzPHkeOJmZnGS%2BPXPObzuAjIyMjIyM%20jIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjJehAt0BV%2BDLLhPjyqGAWR%2Forvx9YFVQTt0BOqLt%20X0IDdKA74Arm3W%2FJIvU2Zr3ld%2F2LIHmhcnmHCH92R6C78beEP7sDXN4hEuh%2BuAIb6A44g%2BfMxPTp%20yEB342%2BN%2Bfv54DkzoRlW0lMAaQv12HqQ4hxRG7uxEMxvVQHq0V8frmsIzPe2FP5PinPAH1sfwB65%20hmSFSmrLiHHFYFEbdVkP5peKAPXo7wHzSwW4vuEgbVVCG%2FfTUpDaMkIFR0h2VJXsHNX803sgtWWi%20NnZbcYB68%2Fei8e9Iastg%2Fum9APXGNSQpVL44l3C%2FrhO1MYfKQefJK39vQOfpwRwqF7Vxv64DX5wr%202YWVJIVq%2Fn4%2BQLj6BgMPJuta4Dr0N4TJugYY%2BPoGwll%2Bd4kiOaFyOTsJn3dQ1MZmXQNVxTk4Q8YT%20qCoObKM%2Ffj7vILicnZIcVSUlVGKqJebsN0RtVJERzIFyB2fINAfmQDmoIqOozZz9BoipVnJilZRQ%20uUOfgJRfFrWxO0oATnK%2F298Djlh%2B3waQ8svgDn0SoA45RjJC5csuE%2FP%2BD0VtdG4N6LPVAerRPwP6%20bDXo3BpRm3n%2Fh%2BDLLktqdJCMUG38%2BRyRzVF%2Bgt1WLH5qSTAOQBJCtefPZ%2FaXgSoxOjhDxptQJUYw%20%2B8U2a6nFAQRcqDxnJo3NIlQVB3ZXaYB69M%2BE3VVqY1mxxgEEqEsiAi9UO%2F585rsSQM87OEPGJ%2Bh5%20y%2B%2FeACnFAQRUqKS2jHA%2FLRW1yf78wMH8UgHqstj7Z40DCFCXBAIqVNmfLz2kGgcQMKHa9ecfrZT9%20%2BQGGztODOVopapNCHEDAhGrXn79dHk2lALO9WHJxAAERquzPlzZSjAPwu1Blf%2F5fA6nFAfhdqLI%2F%20%2Fy%2BCxOIA%2FCpU2Z%2F%2F10JKcQB%2BFarsz%2F%2FrIZU4AL8l93F5h4hp7XhRmxT8%2BSRKCT5BDb59MEgEC6gZ%20yxtmAqrMDPpiLegz1aAKDAHtZ6CwxgFwA1oIbdY4ACauj9%2BSAf0iVMJzxPhJhqgt0P58PlED8yCt%20KBuzMSRGCb6zGhgcCeqyHmx26T9ymsLuKgXfIwwkhBHazN%2FPB%2BE5QtGMX8TqF6FyRzOl489X0TCN%20bgm%2BW4ioOafYiFNXjSip5lBt5BGtYZAQo0SP1kFQMBRIWxVMD7UGc6gc7Nbif9biry4OoHE9AO5o%20pt%2B64HOhSik%2Fn4SzME1qAxKjBAAUVXH48OcyfHigAqU1ZrvnaNUsxqaE4LnbtIgJYcD1CQeJUEDx%20ef4%2FSqyBrgfg88WUZPz5Klok0jW%2FVKDzW39iwa5ShyIFgNIaM5bvL0PKu3nIPmdZAfOd1TCNaeWX%20bkuJQMYB%2BFSoUvLnm4dGCSJd%2FON1TN1YCL3J9alHaY0Zd626gk0nLeWE%2BG4h4PpF%2BKSvUiWQcQA%2B%20ffRLxZ9PdEHg%2BoQDADadrMKcRoZsd5i8oRDdWimREK2EeXAk6OOV0nX9MhT4NkEgsSqQcBYIYUEU%20FCgTAUw8qCIjqGsmUJf1Ln8HZnsxuC4aIKhujPNTHIDPhMrl7CSmr54Qf1iA%2FPlcX4tITRzBC99d%20b9a19CYes7YV49tJbYAgGtzAFmC3ey58X8AnasD1DAOfoAEUrk0fqct6MGeqLSkpTha51jgA893R%209Z9XFwfAJAzx2VzVJ0IlplpiXDlM1EaVmgLmz%2Be7WFb4W09XI6%2FU8bRDq2YRomJRVGl0Oi3I%2Fr0G%202edqMOgGNfgeYYBEhEp0QTDdE2PX5FZUxeF6LYdyPQ%2B1gkKYioEulIGizrpE2qpgbquCOU0Ldk8p%20mP9dd7hYZA6Ug0uNANEqhDZrHAClCPaJWH0iVLv%2B%2FMYeDj9BopSC%2FW%2BHAxvouPQU%2FGfxSnRO7gUA%20MBqNyFz2Gh59%2FnWHgs08WolBN6hBQhhwPcNAVXMgkQogiLY8ZhU0iJ3RjKrhAAMPqtxseeyWmy3B%20H838bbh%2BETAPjQLqhFdUxeGLXyuQfa4GR68Y7S4YVQoa3WIjcHMrHg%2BkhKJPrApQUDAPjgSXpIFi%20db79J2CdR9H0UGuhyddxAF5XP19x1WKOauAqpXNroPj0irc%2FyrX%2BxKlgeiwWAHDXJ1eQ%2FbvYdz1z%20TDqWZGbZPXfjijdw36Mv2H1Pq2ZxcU57YURqFhwBVWAAnW8AlacHfa4GVLljS4QIhoJ5dEtwPUIB%20AJUGHu%2F%2BeB2Lfypza7EIAEk6DVaM0loEC0tUm%2FKDSw6nAqaJbSwOESusCsppWaDDWnldV16%2FoHHz%20DHHqM0egXJIXMFcpn6gR%2FvJ7vJePMwXiUbWkqBCR0TEOz%2B%2FdMRJHLtj3oB2f1Q4J0UpRW6WBx%2FVa%20HhV6DjUmgsoGAcihQTTCVTRaBDOIaeDlsQdVZARzvNK5%2B5ahYPpXa0Esp64acM%2BaIqfTG1dYMDQK%20swZaXKbM0UqwX161exyJUsL4ZJwwigMAnTgUylHveV1XXn30S9GfT5WYhH%2F31DE4U1D%2FnkpBOxUp%20ADwweiSOLLL%2FSPuobs59ttiI%2FCoKf5TUujyKqRQ0YkKV6NmaRVKMEl1bBWFAh2BBwCTGYlWwum%2BZ%20Y5UWJ4l1dGMomMa0EkSafa4Goz8vcHsUtcecHSVo10KB0ckh4HqEgj5QZtek6M84AK9djPAcMX52%20D0jh6fqLV3FQvvNnwFOfjXPjQUIYbDpZhfHrCkTvnTqyF1179nN47p6t63BbxniH77uDK4u1JJ0G%20t3dQYFiSBgM7BIunFgYezKFyMPvKwA2JEh733hRpw77mPNsOoUG001EVKhrGp9uL4gColl2gfPgr%20eDMOwGsGf%2B74BpFIAenk59OnLUb6EV00SNJpRO8tfdX%2BHJTjOOzI%2FAgr318kak%2FSaTAuPQVTMwa4%209NkqBY2pGQPww6bVKKrQ4%2BK1WtQaOeRfysMPm1Zj0exJGJeegjitZV54pqAay%2FeX4a5VV9BuwZ94%20elsxTl2te%2FQH0eAGtIDx%2BQ4%2BFSlgcXCsqzPuc91DAJUDqdirB1B4GtzxDV7tj1cUb%2FXnN3SVUpf1%20UC6%2F5I3LN5uGc6nsczW4a5V4YffT9i%2FRf%2Bh9AIDfftmHlW%2B%2FjDVb96C0xow4rQr9b0rEqHsfwOD7%20piBcG4UdmR%2FhwSnTnbpe47QqPP3YQ5g4%2Bw2EhrvmwbqY%2BxuyNq3G1m%2B%2BQdbhHJH4esVr8VTfIIxO%20rg%2BmOXXVgDtW5jvtR3MY1EltsRcDUKzOdxo5ZpweKzKLUcERUE7LgqT2BTB9P5%2FoF3YSvbg4FSGA%20ZF6mYVFC3%2BbcriUAhJdWzZLP3plH0pJjhf%2BPS08hP2xaTXjOTBry2TvzROc2fsVpVWTlgtnEbBaf%205y5l14rJygWzSa94cV%2BTdBqydpyO5M2NJ3FaldO%2BNPx%2B49JTyPKXZ5CVC2aTOZMzbK5r76VS0MJv%20Zu4X4fT35eJUNhowfT9fOlE7fHEu0b%2BRKO7g%2Fa0CLkybF0MRw%2Bz2Qh8fvCnM5sb0iteSlQtmk6qq%20CrviWTR7klMxLJo9iRgMhmYJ1B5H%2FvcdGZeeYiMiR31p%2BJo5Jp2UXSu2uSbP806%2Fj%2FVV%2FHJHyz0d%20FtX0YHB%2FK7FY30gk3ooDaPYc1Zy9EDb%2B%2FJ3S8NQIMBTMQyJFnpRH%2BoZDpbB8%2FbTkWOzeshaHz1%2FD%20lBfegkYTKjqdEIK5U0ZitoPV%2F7j0FJw8k4Nn3loFpVJp95jm0HPgEKzNOoqcE4cxLj0FAJqck2rV%20LHZvWYslmVkI10bZvE9RFJ55axWGpya51AfKhbUGs7PEth5A9kKXrt8UzRIql7OT8H%2FsFbWxP153%203VjtB0iUEsZH2womlKIqDlM2FGLg%2F11Ct9gI7N6yFrtP5CFtxDj75xOCaaNuxYJVW2zei9OqsPO%2F%20K7E26yhax8X79HsAQOfkXlibdRQ%2F%2F7AFveK1Do9L0mlw9MQph9%2BpIa2ibUVsRatmEWoNPjE0LVSq%203Az2R3EsBf%2FHXq%2FUA%2FBYqHbz80tNFh%2BxROATNTA%2BUT%2FJzz5Xg%2F4f5GPjySosmj0JB3KLmryZ00bd%20ipVbfrJpn5oxAKcuFOCO%2B6f4pO%2FO6DtoBA7kFmHR7EnCU8FKkk6D%2Fx05g7iOCU1ep7K8DDt%2FOuzw%20%2FVvjGyyOLrnmRGD%2Bdx1UqUnU5o16AB4b%2FKXkz7cH1zMM5lExFsM4R7BwVykW7CpFnFaFAz9m48a%2B%20aU1eY%2B6UkTYi1apZrF6xBHc%2FON1rfa2ursTh7G04ffQgcs%2BeRnFJCSprDHj1nf9z2E%2BGYfDMW6tw%202933455RIwVvVP8%2BNyFK17bJz6wsL8OIAd2derHu7V43BTLwoK%2B4mNwYgDgAh%2FAVV4l%2BUbJo4myc%202CbwC6a6l7lfhNCv4pc7kkGd1AQASUuOJUVX811awNhbaKQlx5IrF897ZYF05eJ5smj2JJKWHGt3%20YbRo9iSXr1VRdp0MT00Szh2XnuJ0UbdtzTKSpNM4XUQl6TSk8rUbLAupUTFu3wPjxDbihdWiZMJX%20XPXvKGbcOkvcidduIHyUMuACbSzS3Oc6CDckLTnW4Wq%2BMRs%2BXGhz4%2BZMzmi2yYnnebJtzTKRqOy9%200pJj3b622WwmUzMGCNcYnpok6u%2FFc2fJ0rnTXDZL%2Ffh4bP29DWfdvg98lJLo64QuDGZbZ3ksVLeN%20sXb9%2BT9dl0TwMNczTMiUzCszI31lAfJK9egVr8WeE3%2FarObt8cuPO9E%2FfZiwqvbGo57wHD5f8gre%20fHuxTVCMPY787zsk970Nl86fQcGfuTDU1uJ6cT7CWkRBHRqOFjGt0T6xu13rxItTRwkLv%2BGpSWgV%20HYW9h361%2B7lJOo3d9rXjdIJjgc26BsbDtHbzsChRHAAAKMavhSdxAG6dIGV%2FPp%2BogelBHcBQKKri%200P%2BDfOSV6qFS0Dj%2By0Eh1tQZ14qLcFNiO2HelqTTYMO2nU5jAZrimy%2BW45X%2FvOQwAssejgTUmDit%20CvFtonFj1wSk3zUSt436FzSaUDw5djCWrv%2BhyfNX3tsSt3ZU47PD5fjwgCUreM3Ylhh0gyXQhc6t%20aV62rRfjANw62Hx0PTF%2FN0%2FUxm4sDHgpcxLOwvhUOyCIRqWBx8AVV4UbvfzlGXj8P0ubuIJlNMro%203xXb9p8BYLGtfr3nV7s2SFc4f%2BY4npoyVrieP1ApaAzunYBHHpuOzNUfY90Px5wePz01Au8Mt6SU%20mDgCvZkI5ig6twaKzIJmD0ANn3JW2DtfBdtjjG%2BESmrLiPGjO0Fq6utmSsKfz1AwPtpWMEE1DI5O%20S47FruMXQVFNf823n50sGPTHpafg028PemS85zgO777wCOYt%2BczrgSLuEKdV2V3Rx2lV6BRJIzFa%20iWFJGmH0bIi3i2zYxAGoI6F85Du34gBcNk%2BZf3pPJFJAGvX2zUMihR9hftY1UQT%2Fko8%2Bd0mkB7K3%20Yt6SzyzXmD4GL76%2FzqXzGpN78gjGjxzi1mPeVzQWaa94Lb4aG%2BEwYJsqNQE1HNhtxV5PZ2e3FQtZ%20FgBAaq65XQ%2FAJYO%2FlPLzG8LHqcClWiKTss%2FVYEGDSf%2FUjAEu2Uory8vwwP0PQG%2Fi8dk78zBvWaZH%20Iv144bO4sefNkhCpPY5cKMXJq2JbKFVqAn2qyrIY%2Fu9VKJdf8sk99UY9AJdGVEn68%2BtyhcBQqDTw%20eGxz%2FWivVbNYuHKjS5d5%2BqERKKo0YvMnizFy4lNud6O6uhKPjBzY5HxQCjyzvQxHZ1ge9cyhcrCb%20i%2Fz22czOEtt6AG7EATQ5okrVn8%2F1DRcqn7z8%2FTXRo%2B7Jifc2mWICADsyP8KmrJ%2FxzfpPPRLp%2BTPH%200buT7i8hUsASlG2t9ML1CHMcDO0DmhsH4LSnxGyQpj9fRYNLswRlnLpqwPIG%2B3hq1SyefP2DJi9R%20WV6Gp5%2BehW%2B3bsKge%2F7l9Fij0Tbna%2B%2BODejTq5dLZiQp8e6Buse%2FggLXM8yvn%2B0wDsBsaFKsToXK%20HfxYkv58LjVCsM0918jR0DI8CCMGdEeX1iHYu8NxOsSSuY%2FhkzXr0HfQCKeftWfrOky862ZR2%2BrF%20L2FwxhifRdb7kiMXSoXUFuv83m%2FYqTBOyi%2BDO%2Fhxk6c6FCpfcVWS9fZJCANzXSpv9rkamzz9MwXV%202HPyEnp07SSklzQmNycHw%2B5%2FuEmR7sj8CEPvnYDv9p8Cx1nm6K8%2BMRYPP%2F1qQE1PzeXTwxa7N9Eq%20wMc5LmTsCxzuC9BEHIBDoZr3SLPePjewhTAh%2F8%2FuWrvHaNUsFq3a5PAaHW%2B4AT0HDnH6OdlffY57%20HnoMehOP0hozTh3%2BCU%2BOHYyXlktjE9vmsO1s%2FX0lsf4VKuBgX4A9zvcFsLvql2J%2BPgCQKKXIHOXI%20FPTmi085DWRmGOfFHw5kb8XdYyaKRs2x99ztdD46PDUJwybMQLt27dC6dWtUV1fjxIkT2LZtK3Zl%207ZTUCJxXqkdemRlxESz49sFg9pU1fZIXsVsP4LdtTusB2DRK2Z9vLSFj4gj6LC%2BwKxx3vFH2OH5g%20D24fNNjl%2BWdyty548623MXToUIfH5Obk4KlZT2H79h0Oj%2FE31sATqtQE5aI%2F%2Fd8BN%2BMAbEZUqebn%2084kaoSrIJ4cr7IpUq2axenOWxyLNz7uAEXcNdVmkw4YNxfp165pMh%2B6ckIBvv92OJ5%2BciaVLvVOh%20OU6rwo2JHdAqOgrRURYLSHV1NS7kXcG5P%2FKatEbs%2F7MWo5NDLHlkDOX%2FBbK9fQGc1AMQCZXXVxKT%20ROrti1DRFuM%2BLDlPr2TZf%2BSvWPyqSykY9qiurkTGbb1drtuU3K2LjUg5jsOGL%2F%2BLAwcPIjExCRMm%20jBeF4i1ZshS%2F%2F%2F67xyNrr3gtHhg9EvdNmYV2nbs6PfZacRE2f%2Fw21maux56TtvEY%2BRX1f4ykhSIg%200zq7%2BwL8uAS8vpLQqlDHo41U8%2FNNo2KE%2FozqFmI32HdqxoBmBTQ3Tkdu6rV9%2B3bRNTLXrSUx0VGi%20Y7RqlnzwwQei4%2FIv5bmc6mx9pSXHku3rVnj8%2FY79vNsmWLtXvFYS99jVegDCql%2By%2FvxEjais%2BeZT%20VTbH9IrXYtmXTcdfOuK1f49zy7uU3K2LaE66Y8cOTHxoAoqKxTZdVhOB0aPE%2B2vp2sZi2uPiStzO%20GJ6ahOnTH4dBX40D2VtRcNn9aLUb%2B6Zh677T%2BGHTaqF0UHVtvd%2Bf7xu4vQjcjgMwrp8oVvZ8z1IQ%20vPniw1miryuAkDc3nmjVrM1oo1Wz5OK5sx6PNps%2FWezW6AaAzJw5Q3SN5G5dbI5RKWiyb98%2Bu5%2B5%20fft2tz%2Bz8XdOS44ly1%2Be4XYOlzW%2FSpRu4mKBCZ%2Fe5%2FmN0lbWTxQJlQYc%2BPP3lAbWn89Qloj9Opvp%20xC%2Bv2ixyVAoaWzau83heeiB7K8ZOe8bt8xIT64s2FBcW4OSp0zbHTHv8CaSmpto9v2N882oAlNaY%20sefkJUx%2F%2BT20adcR4wf3wPkzx106NzQ8Aht3H8Pg3gm4Y%2BWVei%2FVgBZ%2Bd6laocrNYPeI1x2N4wBo%20qfrzzaNbOowztbLm%2Fdcdep%2BaIvfkEdw1YrRH9s127doJ%2F86%2Faj8C6cLhLDz55Eysz1yHHTt2oLiw%20vtxlpLaF3XNcRatm0Stei7TkWKQlxyL3Qh6GD%2BqH1Ytfcul8pVKJjbuPoW9iG9yxMh9FdeXPzRkx%20ILqgZvXNU5qKA2Cl6M%2FnbteKyiousJNctmj2JNw77XmPrp978ggGpw3w2Fd%2F8eJF4d%2FtY9vYPWbb%20%2FjPA%2FjOwJsFs374dQ4fqAADXSt0fBIanJmH06Hsx%2BN6HHTozKsvLQHgOFO3coQFYxPr1nl9xS7f2%20uCezDLsnaaFQWIoDK9%2FL8%2F%2F9d1QPoC4OgOaOrBEdT1VxAfXncz3DLJWWYdmfdEJmoc0x86ePwTNv%20rfLo%2BlaRNqd8%2BNmz9XlQ4dooDBvm2NgPADHRURg0aJDw%2F19%2F%2FcXlzxqemoScE4exdd9pPDRrvlOP%20W2h4hEsitRKujcKGbTtx6lIZnq8L7iExSpiHRLp8DW9Cn6222dzCqk%2Ba6TVB9AYJYcAniovd%2Bgs%2B%20USMYgIuqOAz%2FrNBm1JszOQPzlnm2WezxA3uaLVIAyFy3TghSAYAP3nvXprROQ5YuXSrKv1rzxRdN%20foZWzWLDhwuxdd9plzJoPaVrz3748I25WL6%2FTNhCkxvQwu%2FBKoDl%2FpNGqTJWfdLMzVNAhYtLwJiH%20R4s2EPAHXM8wy%2BIJlg0bhnxSaCOoOZMz8PrHX3t0%2FQPZW3H7oMHNFikAFBWXYOXKlcL%2F4zom4PjJ%2000ju1kV0XEx0FDLXrcWYsfX1rY4fP96kwb9XvBa%2FHj3m8dTGXR6aNR%2FDU5Pw2OZrwuYYVgeL32Ao%20i%2B4aQIW3BXOzpbYXBTjeZc%2FTwgPuwvWLEHaCqzTwGPr5dZuAk%2FnTx3g8ku7I%2FEiIhPIWMdFROPbr%20r9C1jRW1V5aX4eRvp9EhLtbmPY7j0COlu10rgZU5kzMwf8WmJgNnvE3e%2BRwkJHXB5N5hQgq1P1Ph%20udu1wpTPiuKeZbDuBkgDAJMwhKI79BcdZE7TWjb28iUMBfOwKEGkRVUcBq64aiPSlQtmeyzSjxc%2B%20i2Hjpnk9eqmouARDht6JynJx5FFoeARSU1NtREp4DiNGDHcoUq2axfZ1K%2FD6x1%2F7XaSA5akw55H7%20sepwBXKKLe5U7s4ovzxZSTgLc5q4jCbdoT8ablkp%2FIMvziXGVSPQMInP6W4YzUVFwzRWJwSaNCzB%20IxyioLHhk%2Fc8KqdDGpW38RUx0VE4tHePU997ZXkZ%2BvXv51Ckw1OTsGrDTkS3jrX7vr%2Borq5EXIwW%20t8arkDneMg1jvyn2eRig%2Bf5WgpUHAEAxUE7eCjq6s6BPYQVAR3emmJvEtUK5HqE%2BmVTzcSoY%2Fx0n%20iPTQJT36vn9JJFJreUhPRFpZXoaM%2Fl19LlLAMrK2T%2BiGR0YOROHZQ%2FXB5pwRxfmX8H%2BvzERYRAu7%20Io3TqoQFU6BFCsBSDmjivdh8qgqH6uqhcmlan46qfJxKLFIAzE3jRCIFGsWjWqOnfFYNhaHA3doC%205tvrv%2FyaXyrw7y3FokdzWnIsvsw6iOiWOrc%2F4vyZ4xg%2BqJ%2Bkk%2B5UChqz%2FjUcz7%2Fzmcs7pviL4sIC%20xMW2xdAEdf2o6sO5qr0qKoppWWgcPSWyqdCqUIoZ%2BKToQqStyiuuNWuJcvPgSCEXf8qGQkzdWCgS%206fzpY7Dr2B8eiTT7q88lnRkap1Vh%2FvQxyLt0Ga9%2F%2FLXkRAoA0S11mDCsHzafqkJemcU0yHdvugqi%20J3A9w2x2wmYGPmkjUsAfEf7WUTRNK%2Bwdf%2BiSHtM2l9oIyrrbcYhGg9DQECQndUaHjp1xyx0ZTVbU%20e%2B%2FFRzHz9RXu98%2FHJOk06N%2FnJjzwrylIyxgfkIVSQ3ZkfoSdWy3ByRqNBi1btUJi9164OX2kUBDO%20ulvhnNu1eKluJa584w%2Fvxn64GeFvd%2FLhtRqo1v06u9Vv4jU%2F65pdl2hTxGlVGDKgN6bNmitKzGtu%20pRKVgkbfxDZI7XMTOnfpjo5JyQhtEY0IrcUSYTDUovL6NdRWV6CmshwV10tQVlqKmuoKlJeVQ6%2Bv%20RXV1%2FR9cZGQUIqNjkJDcE937DfboyeBLivMv4dZeSXafOr3itbjjtgGY9PQr6NOrF0JULHJnW%2BbO%203l5UuVs71eEs2bh1FuF%2F21bf4MEu0Q1Xc45GUU%2FoFa%2FFonffR%2BsOnTFySJrb11QpaNxza3eMfWgK%207rh%2Fqk%2B23JEy%2BXkXkJyUgNIaM0Z1C0HrMBa7%2FjCJfkeVgobexOPIzDh0axXk1a3s7e5K3XU4lCMW%20O9Sjwzf4iqvEuGKwKGXanc423H7cV%2Ft1Wn9MV0nSafDopAfx0KzXPK57%2Bnfhmy%2BWY%2FiEJxCnVWHv%20Y60RE8Igp9iIb89U48ODVYIFRtgSnSMIeu2CV3LnrEmaAqwKymlZoMNaOdSjQwc1HdaKYlMfFbXx%20ndUuxwGYB1kMuEVVHCZkFrosqF7xWiydOw0%2F%2F7AF504fQ86Jw%2Fhh02rMmZwhRKdbcfWaacmx2LZm%20GX67UokZr334jxcpANz94HSMS09BXqkeb%2B62TMUSopWYNbAFcmfH4tvJbZCk0wj%2BfzAU%2BPbBzf7c%20hkmaVtjUR52KFGiikC8xGyzFexuEAVKlJigXX3QaBkZCGBjnWqJ83JmTDk9Nwpa9vznMIi0vLUF8%20rM7l8LzhqUmYM%2F%2BNJiuieAtiqMKpvduxc%2BdO%2FLjvZxRcLYRB3QrDb%2B6Eu4YNxS13jQcVFNL0hfxE%207skjSOjeGwBwfFY7JETbToE2nawS6vk3e68GhoJxVjvRDopUeFtLUV82yKkWndaeotggih0kDowg%20WgW4W50H%2FjbsyEEXN9ICgIKrhSgpuOzw%2FTNH96PGhVF0XHoKjv28G1v3nfaPSM16fP3pu3jq4VHY%20uXMnlEoFBva7Bf363ITCwiIsWLUF%2FUY%2FilaxHXAy%2B0vf98dFOif3ErasXLSnPkaWuqwXdupruJs1%2036F5Iyp3awuRNgCAHfR8kyIFXCyNblw%2FUZyqYuChfPeiQ3NFw%2Flpj%2Ffy3VrsWOvQ9%2B5xI3RtYmE0%20GnDl0kXsP%2FSr3bTfhoxLT8GcN5Y1a3MITygvLUF4eBjA2F%2BUFZ49hHnPPyNsrnbih%2F8iedD9%2Fuyi%20Qw5kb8Ut6RlQKWjkPtseMSEM6FNVYLcUgRsWbeM1CnrlvEfz1Ib7LFihO%2FSHcsynLmnQpYPcjQMg%20uiAYZ8QBAMauLbCbOeptjv2826UK04Hk%2F16Ziekvv4eY6CgU5p0DVOF%2B%2BVyO43Dq8E%2F448xRlF%2B%2F%20jsiYlkjq2R8dk24EAHRpHYIzBdVYmhGDaX3DAROxCJIj4ONUMA%2BPFgzUxYyAAAAOQElEQVTzitX5%20HgXWu%2BLPd4ZLlVzdjQOgioyAyTKHTetou5mBt0nSaQIq0vy8C3j1ibHo3TESwUoGkRoFeneMxI7M%20j0THPTZvMZK7dUFRcQlO7tvpl77NnTISMWEqpNxyG0ZNmoWHn34Vwyc8gRu6pKBdZDBefWIs7rj1%20FgDA1tN1A4qCAt%2BpbgufPD2UH14Gu7EQMPDgk9wPqnfVn%2B8Ml0sOMwOfAqUWxws2DnQV4AjoPyyV%209kZ1C3Ea%2Fe4NZv37cZ9e3xHFhQV4cuxgdLyhE15avh6nLpWhb2IbdO%2Bow6lLZRg2bhq%2B%2BWK5cDxF%20M1jwnKWvOecu%2BLx%2F33yxHAtWbREtPlUKGlo1C5WCRl6pHi8tXy%2FsSbXvTz1MdYtk0rpBkh9HwPxS%20gaA3%2FrAMQm5iExCtjgQ7YIZb13BZQe7GATA%2FW7wYMSEMXkp3vGV3c5k5Jh1TXnBestAXbFzxBhLj%2047B0%2FQ%2FoFhuBDR8uRHlVLXafyMPuE3k48GM2VAoazz77nOi8djrLTWsd3bxM1KYouHwJ02fWp4LH%20aVU4PqsdyuZ3RP68Diib3xG5z3XA0owYJOkso6TexONoviV9mm9nZ%2BGk5932Tjny57uzdQ%2Fg5jbo%20zI33gWopTrfg7oyyWwu%2BYcHWf%2FeLwKhu3jXLaNUsVi6YjSWZWV69blOUl5Zg%2FOAeuO%2FRFwAAn70z%20D4fOleDeac%2BLPFw39k1D38Q2NgvJynLL6rpjlx4%2B6yPHcRg3rJ8obHLhnS1szE9xESym9Q3H0Rmt%20sTQjBioFjaN1u0iLRlRPUdEWfTSAatkFzI3up7i7JVSKZig2fa6ojYQwlrA9O7DbigEDDwVDIXO8%20DkszYqBVNy9rIE6rwpzJGTh7Ic%2FvI%2BneHRvQvVOsEFcQomLRrVc%2Fu3bf6upKnDhfYOOk%2BHb7DkzN%20GICWiX180kdCCB4bfZvIQvLgTWGCmYk%2BVQV2YyHYb4pBn6oS7OHT%2BoZj7%2BP1uXMkhLFJtHMX8%2B1a%20m2uw6XPd3l4ScFOoAMDE9aHorsNFbVxqBEiUrWmGKjFC8ckVIQV2Wt9wrBnrftJYkk6DqRkDsH3d%20CvxeUI7XP%2F7ar8EexfmX8MjIgRgw7H7kleoxf%2FoYLH95BvJK9eifPkw0D7WyYOYElNaYMWXsSKGt%20vLQEJ8%2FkYsUax3sLNJcXp44SzGCA5Q%2F73RGW6QZVaoJikyW2lNlXBsXaAigX%2FSk8%2Bbq1CrKs%2Buto%20%2FMh2h4ZFl63QXYd7tGEv4MHu0oD7cQAkhIH5vlaC6%2BzpbcVYvr8MWjWLxa%2B%2BAF3bOBRczkN5aRGM%20RhMiWkQiQqtFh6Qe6HzjzQGL2ywvLcFbz07B4s%2B3QW%2FiEadVYfWnq5A2wmIBaZg0uHTuNMx4zbLn%20werFL%2BHhp19Fkk6DY3%2BWClOCwrOH0LJTikN7a3Owl3qjUtDY%2B3hbdGtleYwrPnC84RnXLwLmoeIc%20qeZETHniz%2FcJ5n3LbUtUJmocF8NiKGJ4qh3RL%2BxEKl%2B7gTx4U5hQ9Gv%2B9DHEYDB4UuPMJ1y5eJ7M%20mZwhFGVTKWgyZ3IGqaqqsDn22M%2B7SZxWZSmeNiadzJ8%2BRihklnPisF%2F6azAYbMpmqhQ0%2BXZyG%2BHe%20mG%2FXNl2sTBck3CP9wk7EdH8rz0pJJmpstGHet7xZpVc8Vjcx1RLjymFuxQGQKCVM09qChDAwcQQL%20d5UKcQBJOg2ee2YWxj7xYkDC7oxGI7I3fYYPli1B1uEcUcDLzz9sceqKzc%2B7gPS%2B3YWFU5JOg693%207vFp4YiGnz3%2B7jQbr5219DngZpImQ8E8Ihpcn3DP0pAc%2BfOnbgelCPbvaGqFy9lp%2B5fTxF8urwsi%20hrnxwvHfTm5DknQaYSSI06rInMkZ5Mj%2FviM8Z%2FbpSFRVVUG2rVlGpmYMsClpOS49hWz4cCFRKWiS%20lhzrcMT%2FafuXoiK5UzMGkIqy6z7tt5Vta5bZ9FuloMnacbr68o0T2xDCUB6Nioa58W6fa75da%2Fuk%20dXF3Pmc0W%2BHuxgEAFr%2Bv6UGdMFk3cQTrj1Vi8b4qkTlHq2bRL6UTBva7Bd173YLk1CE2%2BfLucK24%20CL%2Fs3oqDP2Zj14%2F7cODsFdHIGadV4cFRQzDthTeFUpY7Mj%2FCsHHTMC49BV98%2FytKS4px6IevsXPr%20Bmz%2Bfq9gAkpLjsXCd5f5JQimvLQEjz8w2CarQatmsWZsS2Frc%2BqyHspVVzyOISXhLCgD7%2FL5zfXn%20O6PZF%2FC4HoCdjFTAkgnw32OV2HZWb7f8jkpBo0NUMFpGaREaGoJQdRCio8S2uppaA6qrK1FZY0DB%201UJU1xpQWG5wGB5oFWiP3n3RIro1amsqoa%2BuRFlpKQquXELmV9twpqAaWjUruoZWzWL04Fts0mN8%20BeE5rHrzBTz32rs23yVJp8H6sVGCrZTOrYHi83y%2FVuVrrj%2FfGV6ZM5i%2Bn0%2B4X8RVAZ2tMBtCwllw%20Q6LAdQ%2BxyR%2FPKTbiUJ4ex%2FINOHiVRlFZjVdqR3mKdSeSgf1uQf8hGeiddpcoWa%2B6uhL7vv0v7rh%2F%20ilc%2FlxCCLZ8twZy58%2BxGok1PjcDLd0QitG4kY45Wgt1U6FeR8nEqmB4TP%2B2YnhOguOMlr2jMKxch%20tWXEuGIwSG29KcPdiTgJYcD3CQd3Y6iwa7Q9TBzBhVITyvU8Kg088htMMWpMBGoFBbXScsMigmmE%20BtFoFcpCxVIoqjKjsIpDWS2PkmoOhZVmlOt55FeYcfYaEUQwPDUJI%2B6%2BGxFaLaJ0cYjt1BWxHZMc%20LvKMRiM%2BXjgby1aswoZtO70WZlhdXYnVb7%2BIZStW2RVokk6Dt4dFCI96cATsjhK%2Fb3AG2MnPD46A%20clqW265SR3htFWY%2Bup6Yv5snavO0cAGJUoJPUINvHwzSOsgm2NYXmDiCkavzhcrW49JT8Oyr7zqN%20yirOv4TVS17G%2B6vWoajS6HH5oYYQnsO%2BnV%2Fh8xXvY1PWz3anK3FaFebdHo4xKaFQ1D2FqCIjFOuv%20giow2Bzva7ieYaL9ogCAvfNVsD3GeE1fXruQL3f8IyEMiFYBEq0EwlmQcBZEzQBKGkRdN3FX0gBL%20AWYCGC2fR9XwgJEHVcNZItZDWBANYzlHzYBoGNHEv7HJDLCIov9NiWjfrh1aaCNRW1ODszlnkXsh%20T1TMrVe8FtOmTMZtI8cLcZ4ufTdCcOHsCez%2Bei1278rCd%2FtPOZxLD%2BqkxqTe4aKoe3AE7K5SSyn7%20QFQJdzM%2F31O8atfyWj0Af8JYYi9NY1oJos0pNmLRnuvYeLLKYQKhSkFjaIIarcNYm4WfVs2ie0cd%20WreMRHRUFDQaDVSqYASr1bheeg3V1dUoLilB7oU8XLha4TQHLEmnwYSUYNzbPRRxEQ3iJOpC75hd%20gd0UxN38fE%2FxugHWuHkG4c82KFTrQT2AQECilDA90FI0zzJxBEfzDcgpMqK42mLViNYwSIhRokfr%20IOGxCwCnrhrw1ckqfP8nHG4m7ApJOg166hjcGh%2BMWzuqxeIEAAMP5lA5mH1lgd21Bg7y8xOHQjnq%20Pa%2FryusXbG49gEDD9QwDN7CF0wVdU1QaeBy6pMfxfANOFxpRUGlGOadCda0BrUMsj%2BewIBqtw1iE%20q2h00CqQEKNEUoxSWLmLO0VAn68FfaISzLHKgG4E0hB%2F%2BvN94tIy71tOzD8uEbV5mmsTKPg4FcgN%20avDtgkEiWEBdNwcrM4EqM4MuMIA6VwOq3Ay%2BWwj4zhrwHYO9VqKRquJA%2F14D6nwNmN%2BqAr5pcmMa%20JnBaYQc%2BCbbfdJ9oyicX9SQO4G%2BBigbfPhh8fDBIyyDw7VSixZpdDDyocjOoIiOo6ybQF2pBFRgC%20%2Flh3SgD8%2BT6pfU4pgqnG%2BwJY6wH4a1%2BAgKDnLZkNDZ4cJIQBQlmQukqGVF3SI2o4S5zuX%2FAP12F%2B%20vg%2BDTnyWdcckDKHouJtFbeaBLZodNf5Xg6riQBUYQOfpQefpLaOldcT8C4qUhDAwDxSv8um4m0X1%209n2BT9ND2TteAqgGwgyiwQ1zkLkq85eAGxYtns5QjOU%2B%2BxifCtWf%2BwLI%2BB5v5Od7im8T7gGwA2aA%20ChankjisByAjaWzy84Mj3M7P9xSfC5UKjqCYATNFbd7aF0DGf9jNzx8w02tBJ03hc6ECANNjLKjo%20BFGbo3oAMhLEXn5%2BdAKYHmP91gW%2FKIWiGarxhNtZPQAZaWE3P%2F%2BOl7wadNIUfhvSmLg%2BFJ0o3i7c%20UT0AGelgNz8%2FcajXg06awq%2FPXva2ZwG2wTzHzo7CMtLCZqdxVmW5j37Gr0KlI9o2a18AGf%2FisN5%2B%20RFu%2Fpz37fTXD9JkEKrytqK1xhQ4ZCcBQlvvSACq8LZg%2BkwLSHb8LlVIE2%2B4LEKME19c%2F1ZdlXIPr%20G24T6uhrf74zAmIfshsHMDjyHxcHIFVICGPZs7YB%2FvDnOyNghkw5DkC6BMqf74yACVWOA5AmgfTn%20OyOgriE5DkB6BNKf74yAClWOA5AWgfbnOyPgznY6ZYwcByAFHPjz6ZQxAeqQmICrgWZYOQ5AAjjy%2059MMG%2FDRFJCAUAE5DiDQSMWf7wxJCBWQ4wACiVT8%2Bc6QjFDlOIDAICV%2FvjMkI1RAjgPwOxLz5ztD%20UkKV4wD8i9T8%2Bc6QlFABOQ7AX0jRn%2B8MyQkVcBAH0OhHlWke3OBIyfnznSFJodqNA%2BgTLscBeAk%2B%20TgWuj3g6JQV%2FvjMkKVRAjgPwJVL15zvDJ0XSvAEVHEGZf%2FmCmL9%2FRWizxgEwv1UFsGd%2FbbiuIZL1%205ztD0p3jOTMxfToSpDgn0F3520JFJ0Ax8WvJuEodIdlHP2A%2FDkDGu0jJn%2B8MSQsVsB8HIOMdpObP%20d4bkhQrYiQOQaT4S9OfLyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjI%2FH34f4DnQZLCUbKg%20AAAAAElFTkSuQmCC%20%22%0A%20%20%20%20%20%20%20height%3D%2215.781592%22%0A%20%20%20%20%20%20%20width%3D%2215.781592%22%20%2F%3E%0A%20%20%20%20%3Crect%0A%20%20%20%20%20%20%20style%3D%22fill%3A%23006699%22%0A%20%20%20%20%20%20%20transform%3D%22scale(-1%2C1)%22%0A%20%20%20%20%20%20%20rx%3D%222.2046731%22%0A%20%20%20%20%20%20%20ry%3D%222.2046731%22%0A%20%20%20%20%20%20%20height%3D%2214.598539%22%0A%20%20%20%20%20%20%20width%3D%2214.6%22%0A%20%20%20%20%20%20%20y%3D%2215.596729%22%0A%20%20%20%20%20%20%20x%3D%22-20.404631%22%0A%20%20%20%20%20%20%20id%3D%22rect11%22%20%2F%3E%0A%20%20%20%20%3Cpath%0A%20%20%20%20%20%20%20style%3D%22opacity%3A0.7811159%3Bfill%3Aurl(%23linearGradient3003-3)%22%0A%20%20%20%20%20%20%20inkscape%3Aconnector-curvature%3D%220%22%0A%20%20%20%20%20%20%20d%3D%22m%2016.547311%2C16.220877%20-6.8853601%2C0%20c%20-1.822591%2C0%20-3.289818%2C1.479199%20-3.289818%2C3.316609%20v%206.71746%20c%200.05899%2C1.434231%200.285919%2C0.527542%200.71786%2C-1.060763%200.502007%2C-1.845951%202.136929%2C-3.459324%204.1279311%2C-4.668496%201.519641%2C-0.922866%203.220687%2C-1.512195%206.316909%2C-1.568259%201.755942%2C-0.03179%201.600963%2C-2.278914%20-0.987471%2C-2.736551%20z%22%0A%20%20%20%20%20%20%20id%3D%22path13%22%20%2F%3E%0A%20%20%20%20%3Cpath%0A%20%20%20%20%20%20%20style%3D%22fill%3A%23ffffff%22%0A%20%20%20%20%20%20%20inkscape%3Aconnector-curvature%3D%220%22%0A%20%20%20%20%20%20%20d%3D%22m%2010.476047%2C27.848959%200%2C-6.634531%20-2.2051841%2C0%200%2C6.634531%202.2051841%2C0%20z%20M%209.3737469%2C20.30806%20c%200.7689821%2C0%201.2476431%2C-0.50946%201.2476431%2C-1.1461%20-0.01433%2C-0.651007%20-0.478632%2C-1.146319%20-1.2330431%2C-1.146319%20-0.754309%2C0%20-1.24757%2C0.495319%20-1.24757%2C1.146319%200%2C0.636676%200.478537%2C1.1461%201.218589%2C1.1461%20h%200.01433%20z%22%0A%20%20%20%20%20%20%20id%3D%22path15%22%20%2F%3E%0A%20%20%20%20%3Cpath%0A%20%20%20%20%20%20%20style%3D%22fill%3A%23ffffff%22%0A%20%20%20%20%20%20%20inkscape%3Aconnector-curvature%3D%220%22%0A%20%20%20%20%20%20%20d%3D%22m%2011.696607%2C27.848959%202.205184%2C0%200%2C-3.705042%20c%200%2C-0.19829%200.01433%2C-0.396375%200.07256%2C-0.538119%200.159417%2C-0.396178%200.522256%2C-0.806504%201.131427%2C-0.806504%200.797962%2C0%201.117191%2C0.608404%201.117191%2C1.500296%20v%203.549333%20h%202.205038%20v%20-3.804176%20c%200%2C-2.037868%20-1.087919%2C-2.986065%20-2.538794%2C-2.986065%20-1.189607%2C0%20-1.711922%2C0.66495%20-2.002097%2C1.117849%20h%200.01472%20v%20-0.962213%20h%20-2.205184%20c%200.02894%2C0.622544%200%2C6.634532%200%2C6.634532%20z%22%0A%20%20%20%20%20%20%20id%3D%22path17%22%20%2F%3E%0A%20%20%3C%2Fg%3E%0A%3C%2Fsvg%3E%0A "Privacy Badger a remplacé ce bouton LinkedIn")
I. Pour la petite histoire▲
Le projet OpenStack a commencé avec le partenariat de Rackspace et de la NASA. Tous deux avaient besoin de travailler avec des téraoctets de données — l'un pour stocker les données de leur plate-forme Cloud et l'autre pour les traitements d'imagerie satellite. Ils ont alors, chacun de leur côté, développé les premiers modules qui sont à la base d'OpenStack — la partie de gestion des VM (Nova) par la NASA et le stockage (Swift) par Rackspace.
Le projet devient open source en 2010 avec la première version Austin sortie en octobre de cette même année. La dernière version, Mitaka, sortie en avril 2016, est la 13e de la série. Openstack est considéré, depuis la version Kilo, comme « enterprise ready » grâce à l'effort communautaire pour y ajouter les fonctionnalités nécessaires telles que la scalabilité, la haute disponibilité et la métrologie.
L'image ci-dessous présente l'architecture globale d'OpenStack. Je vous présenterai ensuite les principaux modules, qui forment la base de la plate-forme.
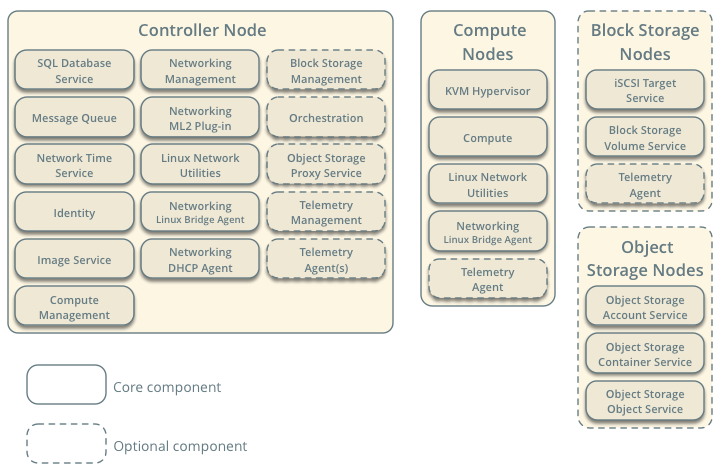
II. Nova - Compute▲
La partie compute d'OpenStack, Nova, permet de communiquer avec l'hyperviseur pour lancer et gérer les machines virtuelles. Plusieurs types d'hyperviseurs sont actuellement disponibles tels que Xen, VMWare (ESX) et Hyper-V. Mais KVM est le mieux supporté par OpenStack. Nova est divisé en composants :
- nova-api : traite les requêtes API venant des clients ;
- nova-compute : daemon nova qui gère les VM ;
- nova-scheduler : coordonne le déploiement des VM sur les machines physiques ;
- nova-conductor : interlocuteur entre nova-compute et la base de données.
Dans une architecture classique, nova-compute peut être installé sur une ou plusieurs machines physiques. Ces daemons communiquent entre eux via le bus de message RabbitMQ. Toutes les demandes sont traitées par nova-api qui délègue ensuite la tâche à nova-compute. Par exemple, lors d'une demande de création d'instance (VM), nova-api fait une demande auprès de nova-scheduler afin de déterminer la machine hôte sur laquelle lancer l'instance (dépendant de sa taille et des disponibilités des serveurs physiques). La demande est ensuite transmise au nova-compute présent sur le serveur afin de lancer la nouvelle machine virtuelle.
III. Swift - Object Storage▲
Swift est la partie de stockage d'objets qui reprend le comportement d'Amazon S3. Il s'agit du deuxième projet mis en open source lors de la release d'OpenStack en 2010. On peut l'utiliser indépendamment des autres modules d'OpenStack afin de créer un cluster de stockage objet. Swift fournit aux entreprises qui cherchent à stocker des données efficacement une solution hautement disponible à moindre coût. Il est divisé en deux parties principales :
- Proxy server ;
- Storage nodes.
Les requêtes venant des clients REST passent par le proxy qui se coordonne ensuite avec les nœuds de stockage appropriés pour traiter la demande. Par exemple, un utilisateur souhaitant stocker une photo fera sa requête par une commande PUT au proxy qui s'occupera d'envoyer l'objet sur le cluster de stockage.
Lors de la sauvegarde d'un objet, Swift en fait trois copies et tente de les stocker sur trois serveurs distincts. Swift retourne ensuite un code réponse au client qui est alors assuré que ses données sont sauvegardées et répliquées.
IV. Cinder - Block Storage▲
Le stockage par bloc est à la base de la sauvegarde des machines virtuelles et de leurs données. Par défaut, les VM utilisent un stockage éphémère (les données stockées sont détruites en même temps que la VM). Cinder, de son côté, permet de créer des volumes persistants de stockage par bloc (block storage).
Les volumes peuvent être attachés à une VM. Le volume est vu comme un n-ième disque dur de la machine. Le volume peut être détaché et attaché à une autre instance en cas de besoin, ce qui est une très bonne solution pour conserver les données utilisées par une application lorsque son instance est détruite.
V. Glance - Image service▲
Glance s'occupe de gérer les images utilisées par les machines virtuelles pour démarrer. Nova communique avec Glance en utilisant son API lorsqu'une instance est déployée. OpenStack supporte plusieurs formats d'images, parmi les plus connus, on retrouve :
- raw : format de base, non structuré, brut ;
- vhd, vmdk : reconnu par la plupart des hyperviseurs (VMWare, Virtualbox, Xen…) ;
- vdi : reconnu principalement par Virtualbox et QEMU ;
- iso : format d'archive d'images ;
- qcow : utilisé par qemu pour du Copy-On-Write.
D'autres formats d'images sont supportés, par exemple celui utilisé par Amazon (AMI Amazon Machine Images). Les images peuvent être stockées sur le système de fichiers, dans Swift ou sous forme de volume Cinder.
VI. Keystone - Auth▲
Keystone est le gestionnaire d'autorisation des utilisateurs OpenStack. Un client authentifié récupère un token d'autorisation basé sur ses droits qui sont enregistrés sur la plate-forme. Ce token lui permet de communiquer avec l'ensemble des modules exécutés par OpenStack.
Keystone permet de gérer l'authentification de manière classique avec une base de données MySQL, ce qui n'est pas recommandé en terme de sécurité. Une meilleure alternative est de laisser la responsabilité de l'authentification à des outils externes avant que Keystone ne génère son token. Plusieurs intégrations sont disponibles telles que LDAP, Active Directory et Kerberos.
VII. Neutron - Software Defined Network▲
Il gère toutes les interfaces réseau qu'utilise OpenStack. Le prérequis lorsqu'on lance une VM est de créer l'architecture réseau sur laquelle elle sera déployée. Cela consiste donc à définir un réseau et son plan d'adressage (subnet) pour ensuite y attacher un routeur. Celui-ci permet l'association d'une adresse IP flottante à la VM afin d'autoriser les communications vers le monde extérieur.
Différentes méthodes peuvent être mises en œuvre pour segmenter l'architecture réseau, via l'utilisation de plugins tels que OpenVSwitch et Modular Layer 2 (ml2). Par exemple, dans un réseau en VLAN, chaque projet (tenant) se voit assigner un numéro de VLAN. Cela permet alors au commutateur virtuel (OpenVSwitch) de transmettre les données échangées entre les VM d'un même réseau sans entrer en conflit avec les autres projets ayant le même adressage.
Tout comme les autres modules, Neutron possède également une interface d'API. Très utile pour les administrateurs, elle permet d'avoir une vue abstraite des ressources utilisées, telles que :
- Le segment réseau où se trouve la VM ;
- Le subnet ou plage d'adresses en IPv4 ou IPv6 configurable pour le réseau ;
- Le port de connexion entre l'interface réseau (NIC) d'une VM au réseau virtuel.
La création des topologies de réseau peut alors être multiple et complexe, au gré des besoins de l'utilisateur du tenant. L'API permet ainsi aux administrateurs d'être plus flexibles lors des personnalisations faites au niveau des configurations.
VIII. Ceilometer - Métriques▲
La récupération de métriques de la plate-forme OpenStack est prise en charge par Ceilometer. C'est un service de collecte de métriques pouvant être utilisé pour de la facturation clients (CloudKitty), du suivi de ressources (Gnocchi) et de la remontée d'alertes (Aodh).
Avec Ceilometer, chaque projet envoie ses événements (création, suppression d'instance…) par le biais du bus de message. Les informations sont collectées par des agents (agent-notification).
IX. Horizon - Cockpit▲
Le tableau de bord OpenStack est fourni par Horizon. Il permet d'administrer les différents composants dans un navigateur. Chaque utilisateur authentifié peut déployer une machine virtuelle, ajouter une image, créer un volume, etc. D'autres fonctionnalités peuvent encore être ajoutées au tableau de bord pour les nouveaux composants qui continuent d'être développés.
X. Heat - Orchestrateur▲
Enfin, nous avons l'orchestrateur Heat qui permet d'instancier automatiquement les instances, les différentes briques du réseau logique, ou tout autre composant cloud disponible sur Openstack. Le projet Heat a été initié au départ afin de reprendre le fonctionnement de CloudFormation, qui permet de créer les ressources liées à AWS. Basé sur le formatage par template, il possède sa propre syntaxe nommée HOT (Heat Orchestration Templates) en YAML. Grâce au composant heat-api-cfn, il supporte également les requêtes du style AWS CloudFormation (format JSON).
Le template HOT permet de définir des collections de ressources, appelées Stack, que l'on souhaite déployer sur un projet. Il permet de définir, par exemple, deux instances tournant sur un réseau privé connecté à un routeur. Lors du lancement de ce template, la stack complète est déployée sur un tenant automatiquement.
La liste des ressources pouvant être déployées par HOT est longue et une, particulièrement intéressante, permet de lancer des scripts de configuration pour installer des applications directement sur les machines virtuelles.
XI. Conclusion▲
Vous possédez maintenant une vision globale du fonctionnement de la plate-forme d'infrastructure OpenStack. En fonction de vos ambitions, vous pouvez tirer parti d'OpenStack soit pour des besoins de tests à l'échelle d'une équipe, soit scaler jusqu'à maintenir un fournisseur de Cloud Public. L'investissement en matériel, temps et expertise nécessaire ne sera évidemment pas le même.
OpenStack est un projet très vaste avec de multiples usages. Selon vos besoins il nécessite des connaissances pointues sur un certain nombre d'aspects du Cloud Computing. Nous reviendrons plus en détail sur des cas plus pratiques dans d'autres articles, mais vu l'ampleur de cet écosystème, cet article de préambule était un passage obligé.
XII. Note de la rédaction Developpez.com▲
Tous nos remerciements à Wescale pour l'autorisation de publication de ce tutoriel.
Nos remerciements également à Winjerome pour la mise au gabarit Developpez.com et Jacques Jean pour la relecture orthographique.